

データ分析をデータサイエンティストの手から解き放て~統計家・西内啓氏が起業に参画したワケ

統計家 株式会社データビークル取締役 西内 啓氏
東京大学医学部(生物統計学専攻)卒業後、東京大学大学院医学系研究科医療コミュニケーション学分野助教、大学病院医療情報ネットワーク研究センター副センター長、ダナファーバー/ハーバードがん研究センター客員研究員を経て、2010年よりさまざまな企業のデータ分析プロジェクトに携わる。2014年11月、株式会社データビークルの創業に参画し、取締役に就任。東京大学政策ビジョン研究センター客員研究員も兼任する
ベストセラー『統計学は最強の学問である』の著者であり、ビジネスにおけるデータ分析の専門家として知られる統計家の西内啓氏が、インフォテリアで常務執行役員を務めた経験を持つ油野達也氏(代表取締役CEO)や、投資家・ブロガーとして活躍中の山本一郎氏(財務担当取締役CFO)とともに、昨年末、データ分析専門の新会社データビークルを設立した。
2015年4月には、同社初のプロダクトであるデータ分析ソフト『DATA DIVER』を正式リリース。これから事業は本格稼働することになる。
長らくアカデミックな世界で医療や社会保障をテーマに統計データと格闘していたはずの西内氏が、なぜ新会社の創業に参画したのか。実機を使ったハンズオンセミナーで忙しい西内氏を訪ねた。
「成果が出せない」という声にどう応えるか
「2010年にアメリカから帰国した後、知人のご紹介などから、ずいぶんいろいろな企業のデータ分析をお手伝いさせていただくようになっていました。ただ『統計学は最強の学問である』を出して以降、企業にお勤めの方からの問い合わせや引き合いが増えたのは確かです」
西内氏は、知人以外に連絡先を公開していなかったことから、著作を通じて西内氏を知った読者からの相談が出版社に届くことが度々あったと言う。
「そうしたご縁から実際にお話を聞いてみると、『分析ツールを購入したし、優秀なコンサルや専任担当者も雇ったのに一向に成果が出ない。どうしたらいいのか』という、切羽詰まった現場担当者の苦悩をたくさん伺うことになりました」
統計学の専門家として、こうした声に対して何とか応えたい。自分1人で多数の企業の課題にあたる生活は多忙を極めた。しかし、だからと言って、数多くの人材を抱えて「人月商売」をする気にもなれない。
「これまでの知見やノウハウを使えば、短期間でデータサイエンティストを育成することも、企業に派遣するようなビジネスもできたでしょうが、自分の関心はそこにはありませんでした。データ分析を多くの人に使ってもらいたいという気持ちの方が強かったんです。それに、自分の前に来ていたデータサイエンティストたちがその期間、いったい何をしていたかを見せてもらうと、彼らは分析自体よりもデータの『前処理』にほとんどの時間を費やしているというところにも違和感がありました」
「前処理」とは、データを集めた後、分析に資するよう加工するためのプロセスを指す。プロジェクトの規模にもよるが、この前処理に8割から9割の時間と労力を割くことも稀ではない。
西内氏はこうした前処理の工程を、可能な限り素早く終わらせるためのノウハウを密かに体系立てていた。そして、数年前から分析案件で協業していた山本氏との会話の中で、「このノウハウをパッケージ化すればこれまでにない分析ツールができるのではないか」という話になったのという。
その後、山本氏からこのツールのビジネスモデルについて相談を受けた油野氏が、アイデアの先見性を見抜き、高く評価したことで、統計家と投資家、営業のプロからなるデータビークルの座組が実現することになる。
『DATA DIVER』は下処理工程を大幅に短縮する

自身初の「共同創業者」として、成し遂げたいことを語る西内氏
『DATA DIVER』が可能にするのは、分析に欠かせない下処理工程を圧縮し、アウトカム(求める成果)に対して何の要因(説明変数)が影響しているかを明確にすることにあると西内氏は言う。
「これまでデータサイエンティストと呼ばれる人々は、『どうすればもっと儲かるのか』という企業の課題に対して何カ月も掛けて関係者へのヒアリングを行い、仮説を立て、その仮説を表現できるようにデータを加工するという地道な作業を繰り返してきました」
ただ、どんなに長時間ヒアリングをしたとしても、仮説につながるような言葉が引き出せるとは限らない。また、分析手法には詳しくても、業界の知識がない人間は不適切なアウトカムを設定してしまうこともある。
そして、現状のデータからアウトカムに影響する説明変数は一見いくらヒアリングしてもし切れないほど無限にあるように思えるが、実際のところ、業界や分野を問わずある程度はパターン化できるものも少なくない。
「それなら設定されたアウトカムに対し、今あるデータから考え得る説明変数を数百個だろうと数千個だろうと自動的に生成し、その中から有望なものだけを数十個ほど取捨選択してアウトカムとの関連性を提示すればどうかと考えました。『DATA DIVER』のエンジンには、多変量解析手法をベースとした統計解析ノウハウをつぎ込んでいます。これまで仮説を立てようとすら思わなかった、意外な説明関数をいち早く見つけ、次のステップに進むことができるわけです」
西内氏は、粗いながらも一定の分析結果を前にして関係者間でディスカッションを行う場合と、何もベースがない中でヒアリングするのとでは、得られる情報に劇的な違いがあることを何度も経験していた。後者の方が、関係者の経験やインスピレーションが刺激され、利益につながるヒントやアイデアが出やすくなるのだ。
「『DATA DIVER』にデータを取り込めば、最大化したいアウトカム(例えば売上など)を選び、その店舗ごとの違いと関連する要因が見たいのか、それとも顧客ごとの違いと関連する要因が見たいのかといった分析軸(解析単位)を選択するだけで、数十秒程度で結果を出すことができます。
しかも『どの指標が1上がると売上がいくら上がる傾向にある』というように、日本語で概要を説明してくれるので、専門家でなくても結果の意味が分かり、活発な議論を促すことにもつながります。『DATA DIVER』は、データ分析を行う上で重要な最初の一歩を踏み出すにとても有効なツールなんです」
もし機能にない高度な視覚化が必要なら、BI(ビジネス・インテリジェンス)ツールにここまで加工したデータを渡し、深堀りすることもできる。機械学習的なアルゴリズムで今後の予測を自動化してもいい。
『DATA DIVER』は、データと現行の分析ツールの間にあるギャップを埋めるだけでなく、組織にPDCAサイクルを根付かせ、状況を前に進めるために生み出されたプロダクトといえそうだ。
最終目標は誰でも使えるプロダクトを作ること
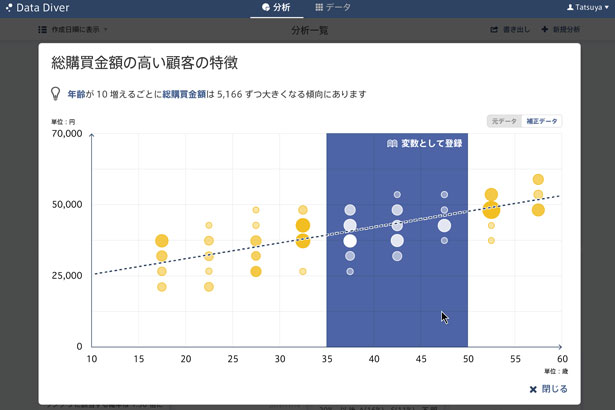
解析結果は自然な日本語で表示。グラフィカルで洗練されたUIがユーザに親しみを感じさせる(画面は開発中のもの)
西内氏は『DATA DIVER』のようなツールが普及し、データ分析の前工程に掛かる負担が軽減されることによって、いずれはデータ分析の活用とイノベーションのスピードが加速すればと期待を寄せている。
「今回、起業に参画した理由を一言で申し上げれば、『データ分析の裾野を広げたい』ということに尽きます。全ての社会人が自分の仕事をデータに基づいて改善することが当たり前になれば、その社会人たちは一人の住民や有権者として、自治体や国の行政に対し、エビデンスに基づいた政策立案を促すようなことにもつながるかも知れません。
一方で、機械学習や応用数学を身に付けたデータサイエンティストたちには、面倒な前処理よりもその専門性を発揮してもらうことに集中してもらえるはずです。いずれもイノベーションのスピードを上げるには有効な方策だと思っています」
こうした流れが生まれることによって、データを使ってビジネスを良くしようと苦労している人々の追い風になったり、発言力に重みを増すことになったりすればうれしいと西内氏は言う。
「『DATA DIVER』については、今後数年かけて機能を高めていきます。またデータの収集やマネジメントを行うソフトの開発も行う計画です。当面は比較的大きな企業のデータ分析担当者の方を中心に活用していただくことになると思いますが、最終的にはスーパーの店長が商品の発注やチラシの出稿を最適化するために使ってもらえるようなプロダクトを提供するのが目標です」
誰もがデータ分析の恩恵を知り、活用することで生産性は上げられる。データサイエンスの第二幕はすでに始まっているようだ。
取材・文/武田敏則(グレタケ) 撮影/桑原美樹

RELATED関連記事

「n個の歴史に対してn+1番目となるものを作りたい」データ解析で不動産投資の常識を覆すリーウェイズCTOの野望

SIビジネス崩壊後も生き残る、「多芸SE」への道

「まずは可視化コード書きから」めんどくさがり屋必見!できるだけ作業時間を減らすデバッグ術【五十嵐悠紀】

「スクラムでは遅過ぎる」との声も。Google主催『Startup Tech Night』で聞いた、少人数で高速開発を進めるコツ

「エンジニアは今すぐディープラーニングを学べ」松尾豊氏が見据える、日本がシリコンバレーを追い越す日
JOB BOARD編集部オススメ求人特集








RANKING人気記事ランキング

孫正義に未来を宣言した20代の野心。「No.1」を譲らない木口佳南を突き動かす原動力

「休める仕組み」が強い開発チームを作る。主力エンジニアの3カ月育休を支える“失敗を許容する”空気感

南場智子「ますます“速さ”が命題に」DeNA AI Day2026全文書き起こし

「未来はすでにここにある」暦本純一が最終講義で語った、これから10年の技術者の仕事

AWS認定資格12種類を一覧で解説! 難易度や費用、おすすめの学習方法も
タグ
そのほかのタグを見る



