ひろゆきさんが今話したいエンジニアに聞いてみたかったことを聞いていく本連載。話題のプロダクトを、ひろゆきさんはどうみるのか? 「僕ならこうつくる」というひろゆき案も飛び出すかも!? 「世の中をあっと言わせるプロダクトが作りたい」エンジニアのみなさんにヒントを届けます。

米国優位が揺らぐ?ひろゆき「CPUの進化でGPU神話って崩壊しません?」【AI研究者・今井翔太が回答】
GPUを大量保有できる国が、生成AI時代の勝者になる―。
それほどまでに「GPUを確保できるか」どうかが、生成AIの進化には欠かせない。
事実、GPUで最大手の半導体メーカー・エヌビディア*には、世界中の企業が供給待ちの列をなしている状態だ。
*AIの計算に使う画像処理半導体(GPU)で世界シェア約9割を誇る半導体メーカー。2024年11月6日時点で、Appleの時価総額を超え、世界首位に立った。
現在はそのエヌビディアを抱える米国が膨大なGPUを保有しており、AI開発でも世界をリードしている。
ただ、そんなGPU神話が「揺らぐのでは?」と話すのが、2ちゃんねる開設人で、ひろゆきさんだ。

GPUではなくCPUでそれなりの速度で計算するBitNetのLlama8B版が出たようですが、実用に耐えうるとすると、GPUを大量に買い付ける事が出来たアメリカの会社が強いという流れが崩れるかもしれないと思うのですが、どうですかね?
この疑問について、AI研究者で、最新のAI動向にも詳しい今井翔太さんに答えてもらった。
目次
CPU需要が上がるのは間違いない
今井さん:まずこれは、ひろゆきさんの質問には含まれていないのですが、CPUの需要が上がるのは間違いないです。
一方で、 Bitnetやその他GPUを必要としない小型モデルが乱立しても、即座にGPUの需要が下がるのは考えにくい。なので、GPUを大量に持っているアメリカの会社は少なくともAIの開発段階では当分強いままだと思います。
生成AIの処理には、学習段階(大企業がAIにデータを食わせて能力を上げていくフェーズ)と推論段階(一般ユーザーが生成AIを使うフェーズ)があるのですが、Bitnetなどの手法が関係してくるのは後者の推論フェーズの方です。

今井さん:ものすごく細かい話になるのですが、学習段階でBitnetのような高速度の低精度パラメータの量子化技術を使うことは基本的にできません(量子化技術全体はともかく、Bitnet自体は学習時から量子化しているので微妙に複雑ですが)。なぜなら学習時にこれらを使うと、エラーの蓄積が大きくなりすぎて(超細かい話をすると、学習は誤差逆伝播という手法を使っているのですが、これは掛け算の連続なので、誤差が掛け算のたびに大きくなります)、学習されたパラメータが使い物にならなくなります。
一方で、一旦学習が終わったあとのニューラルネットワークのパラメータには、実用上必要ない冗長な部分が含まれていたり、限りなく0に近い値が含まれていたりするので、これらの値を0にしたり1にしたりする、あるいは小数点以下の精度を落としたりすると、大して性能は落とさずに性能を上げることができる……というのがBitnetなどの量子化技術(あるいはちょっと似た、パラメータを削除する枝狩りという技術)の背景にある考えです。
現在の生成AIは、スマホやPCなどのエッジデバイスで動かすには大きすぎ、遅すぎますし、事業者のサーバーで動かすにしても、電力消費が大きすぎます。なので、今後もBitnetのような手法はどんどん出てくるでしょう。
このあたりはかなり進化していて、去年のGPT-4レベルのものが、今では僕のMacPC上で動きます。手法の発展もそうですが、もちろんハードの進化の方も重要なファクターなので、エッジデバイスに積むCPUなどの処理装置は史上稀に見る技術スピードと需要になっています。

今井さん:GPUの需要はどうかという話に戻るのですが、Bitnetなどの手法がどれだけ発展しようが、CPUの需要がどれだけ増えようが、GPUの需要が減ることは、少なくとも現在のニューラルネットワークをベースとしたAI技術が主流の間はほぼありえません。
なぜなら、AIの学習段階については、Bitnetなどの推論時の効率化とはまったく逆行して、どんどん大規模化が続いているためです。この「学習の大規模化」については、三つの流れがあります。
AIの学習の大規模化を理解する三つのポイント
【ポイント1】スケーリング則
今井さん:まず一つが、生成AIブーム以前の2020年に発見されたスケーリング則というものです。スケーリング則が言っていることは、「学習データと、計算量と、ニューラルネットワークのサイズという三つの要素を増やし続ければ、AIの性能は無限に上昇し続ける」というものです。
AI研究というのは、僕みたいな研究者が美しい理論を考えたり、ニューラルネットワークの形を工夫したり、いろいろとスマートなことをやりながら発展してきたのですが、このスケーリング則が言っていることは、「このようなスマートな工夫はあまり性能向上に関係なく、上述の三つの要素を増やすためにどれだけお金がかけられるかが重要である」ということです。
ここでお金がかかるのは、計算量を増やすためのGPUで、要するにGPUをひたすら買ってAIの学習に使えば、勝手に性能がよくなっていくという話です。
【ポイント2】表に見えているGPU需要はごく一部
今井さん:二つ目は、このようなスケーリング則に従う大規模学習によってAIの性能が上がっていく傾向は、生成AIに限らないということです。生成AIというのは、あくまでもAI研究全体の一分野であるわけですが、実際には生成AI分野以外にも発展が望まれている分野は山ほどあります。
例えば今年のノーベル賞のように「科学的発見のためのAI」もそうですし、ロボット操作とかもそうです。つまり、GPUの需要で表に見えている生成AIへの利用は未来の需要から見るとごく一部なのです。
結局、ニューラルネットワークの大規模学習を行うことには違いがないので、GPUが大量に必要になってきます。ロボットとか科学的発見とかになると、それこそ安全保障の問題になってきますので、GPUを調達できないことは、それこそ国家の運命を左右するかもしれません。
【ポイント3】推論時スケーリング
今井さん:最後はここ2カ月くらいで研究者の間で重要視され始めた説で「推論時スケーリング」というものです。先ほどから言っていたように、GPUを大量に必要とし、その量に応じて性能が上がっていくスケーリング則というのは、学習時だけの話とされていたんですが、実は推論時にも、大規模に計算を行う(つまり、AIに長く考えさせる、何度も生成AIの処理を裏側で実行すること)が性能向上に寄与することが明らかになってきました。
これは9月にOpenAIから公開されたOpenAI o1というAIが発端です。このAIは、博士号取得者レベル(つまり、この文章を書いている僕くらい)の能力を持っているんですが、その能力を得る鍵が、推論時に大規模な計算を行うことだったのです。
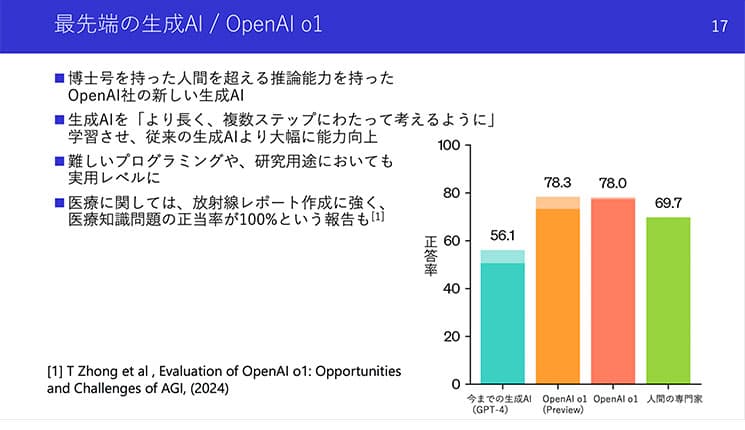
今井さん提供資料
今井さん:しかもこの推論時の性能は、計算量を増やせば増やすほど上がっていくという法則……つまり「推論時スケーリング則」が確認された、ということになります。
よって、最初の方に言っていた「学習時と推論時で分けて考える」という説が実は微妙になって、「推論時にすら大規模な計算が必要かもしれない」という流れができていて、結局推論時にもGPUを積んで力任せに計算したほうがいいかも……と研究者は考えるようになっています。
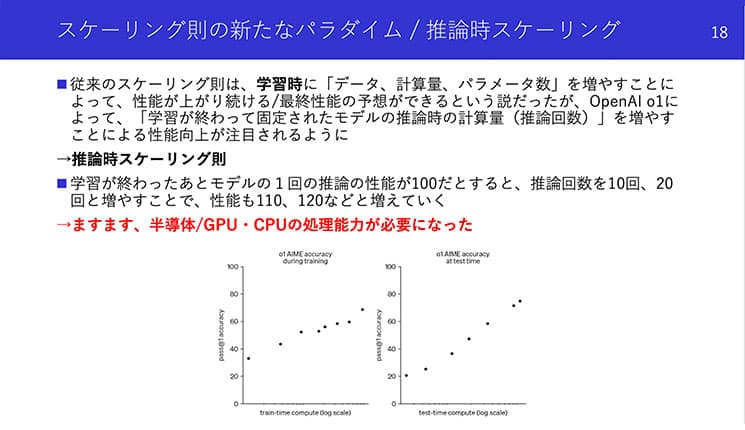
今井さん提供資料
今井さん:以上の3説により、GPUの需要は、Bitnetなどの推論時効率化の手法がどれだけ発展しても減らず、むしろAI研究の流れを踏まえると上がり続ける、というのが研究者としての意見になります。
一般人にとって、OpenAI o1は「性能が良すぎて使いこなせない」
なるほど。推理時スケーリングですが、今井さんが教えてくれたレベルの精度を求めるのって、あくまでも一部の研究機関などであって、実態としては一兆円投資をしたアメリカのAI企業のAPIを使う形で十分なのでは?とも思うんですよね。
結局、一般人は高性能スマホを持っていてもYouTubeを見たり、Xをしたりするくらいなので、GPT4を超える性能は要らないのではと。スマホで動くオープンソースのLlamaで十分かなと。
今井さん:ひろゆきさんの知識には驚かされます、、、。確かに、その見立ては長期的に考えるとかなり正しいと思います。
推論時スケーリングによってAIが「博士号レベルの知識を持っている」と言っても、普通の人間は「では、そのAIに何を聞くべきか」が分かりませんし、そもそもそんな高度な問題に日常で出くわすことはまずないですからね。
実際、o1が出てから2ヶ月程度、僕はいろんなところで「o1を使っているか?」と聞いているのですが、使っている人はほぼ皆無です。僕が講演などで出向く場所は比較的賢い人が多い(投資、金融、医療)はずなのですが、そのような層でも使いこなせていないのが実情です。使っているのはソフトウェア開発に携わるエンジニアの中でも上位層と、僕のような研究者くらい。なので、o1くらいになると、もう性能がオーバーキルなんですよね。
一般人が「ありがたい」と感じる生成AIの限界レベルは今年5月に出たGPT-4oくらいの性能だと思っていまして、たぶんそれ以上性能が上がっても、例えばo2みたいのが出てこようと、ボジョレーヌーヴォーのワインみたいに、何が変わったのかのかよく分からないと思います。

超最先端の開発レースでもGPUは枯渇している
そうなると、生成AI開発レースからほとんどの機関が脱落してGPUの総需要ってやっぱり減りません?
検索エンジンが日本だけでもgooやInfoseekなど複数社出た時代がありましたけど、今は数千億円の投資ができるアメリカの数社に集約されてしまいました。それと似たような話かなと思っていて。
つまり、AIの学習段階で投資できるのは、アメリカの数社に寡占されてるので、GPUの個数自体は世界中の会社が投資に参加する時代よりも減るのではないかなと。
今井さん:そうですね、現時点でこのレベルのAI開発の競争に参加できているのは、それこそGAFAMと、そこの支援を受けているOpenAI、Anthropic、イーロン・マスクが作ったxAIなどの企業のみで、少なくとも僕の周りに本気で推論時スケーリングでこれらの企業に挑もうとする人たちはいないようです。そもそも、推論時スケーリング以前の学習時のスケーリング則の競争の時点で、一度の学習に200億円以上使うようになってしまっているので、もう日本の研究機関はほぼお手上げです。
だからと言って、生成AI開発レースからほとんどの機関が脱落してGPUの総需要が減るかというと、これは少し考えにくいです。
まず第一に、現時点の最先端GPU(NVIDIA H100*と、まもなく提供開始予定のBlackwellシリーズ)からして全く供給が追いついておらず、買いたくても買えない状況なのです。
*NVIDIA H100は、AIモデルのトレーニングや推論、シミュレーションを高速に行うために開発された高性能GPU
今井さん:もし、どこかの機関が生成AI開発レースから脱落してその分のGPUが浮くとしても、先ほどのGAFAMと愉快な仲間たちが「なら、余った分は全部よこせ。俺たちはもっと必要だ。金はある」となるだけだと思います。
あとGPUは、大規模生成AI開発だけではなく、普通に僕たちみたいな現実的なサイズのAI、生成AI以外のAIを作る時にも普通にいくつか必要なのですが、その分ですら不足状態です。我々は普段、国の機関のGPU搭載共有スパコンを使うのですが、僕が松尾研で博士学生をやっていた時代も現在も、研究室の人たちは「他の機関がGPUで学習しているせいで、我々の使用可能な枠がない。いつになったら使えそうか」という会話を普通にしています。
とにかく、GPUというのは上位の最先端開発レースでも、それ以外の研究でも、最近は不足している状況です。
「戦闘機と竹槍」くらい違う、GAFAMとそれ以外のGPU保有率
今井さん:GPUの総需要が減らない理由の二つ目は、既に現時点でGAFAMと愉快な仲間たちのGPU独占比率が高すぎて、それ以外の機関の需要の多少の変動はもはや総需要においてあまり関係ないという状況があるためです。
日本の研究者にとっては悲惨な話なのですが、下記は日本の最高峰と、GAFAたちを比べてみた資料を参照にしています。

今井さん:このように、桁からして二つか三つ、下手すれば四つくらい違います。おそらくイーロンのxAIだけで日本に存在するH100の総量より多いです。松尾先生は「戦闘機と竹槍」と表現しています。
ひろゆきさん:GPU独占比率が、桁が違い過ぎて面白いです。。。勝ちようがないっすね、、、
今井さん:さらにEpoch AIという、AIと計算資源の関係を調査している割と有名な機関があるんですが、この機関による推計が下記の画像1です。GAFAMとその関連組織だけで、世界に流通する先端GPUの過半数を占めているくらいになります。しかも今はこの推計よりももっと増えています。
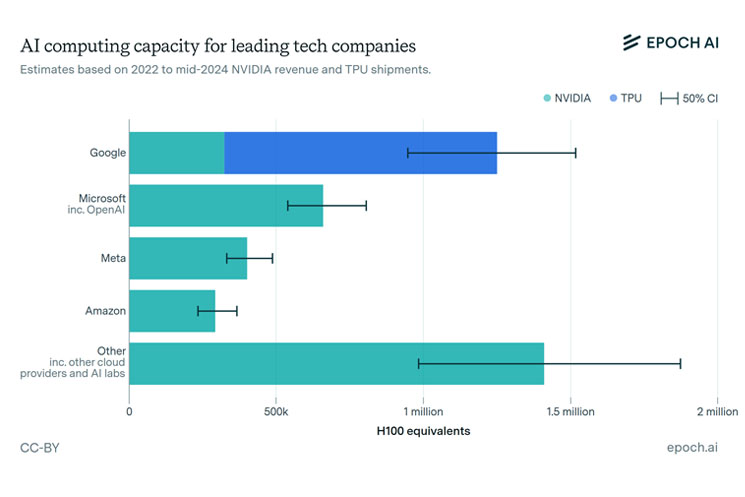
画像1 Epoch AI資料参照
今井さん:GPUの総需要が減らないと言える理由の三つ目は、今後のAIの開発レースが今後どうなるか、という話になります。
ひろゆきさん:気になりますー。
今井さん:まず、今の生成AIの開発レースは大雑把に二つの領域に分けられると思います。一つは先ほどからも話題にしているような、全ての計算資源を注ぎ込んで、学習時も推論時もGPUを使いまくる最先端の生成AIの開発です。
もう一つは、今年5月に出たGPT-4o(テキスト、動画、音声、画像全てを入出力できて、動作も高速なマルチモーダルモデル)を最高到達ラインとして、他の機関がそれをどう再現するか、いかに小型化できるか、オープンモデルが出るか、収益を上げられるサービスを設計できるかというレースです。
後者のGPT-4oは、一般の人が恩恵を感じることができる生成AIの最終ラインで、これ以上進化しても、正直ありがたみはあんまり分からなくなります。なので、一般向けのアプリケーションを目指すならここがゴールです。
そして、おそらくここまでは、中堅以下の研究機関でも技術発展と時間をかければ到達可能なラインです。MetaのLlama4はたぶんこの領域に入ってくると思いますし、Googleもそろそろ追いつきそうな気配です。
そして、この二つが追いつけば、ノウハウも蓄積されるので、他の機関もどんどん再現しようとする。生成AIのモデル自体のカスタマイズの余地も、アプリケーション開発の余地も山ほどあるので、ここから一年くらいはこのラインで多くの企業が切磋琢磨し、キラーアプリケーションみたいなものが開発されるのではないかと思います。
僕もこの領域で研究開発をしています。このレースは、どこかでGPUの需要が落ち着く可能性がありますが、現在はここにもGPUが大量に必要です。
生成AI開発レースの最終到達地点
結局のところ、最先端生成AIの到達地点はどこにあるんですかね? そもそもこんなにめちゃくちゃGPUを注ぎ込みまくる競争がこのまま続くのか、GAFAの中から降りる企業も出てくるのでは?
今井さん:それを考えるには、開発経験のある第一線のAI研究者2人が唱える二つの説(以下)はコミュニティ内でも広く参照されていて、参考になると思います。
【1】AnthropicのCEO ダリオ・アモディが書いた文書

【要約】あと5~10年で人間の寿命は150年くらいになる可能性が高い。また、精神疾患も治療できるようになるだろう。感染症、癌の撲滅も可能と考える。今まで人間の科学者が50年〜100年かけて達成してきた進捗がAIによって5~10年に圧縮されるということだ。
Machines of Loving Grace【2】元OpenAIのスーパーアライメントチームにいたアッシェンブレナーの文書

【要約】GPT-2からGPT-4までの間に起こったことは単に学習の計算量を増やしただけで、単にそれをもう一度やればいいのだ。それだけでAIがAI研究をするくらいに賢くなる。こうなればAIがAIを生み出す知能爆発が起こり、AIの性能は加速的に上がる。こうやって誕生したAIを科学、経済のあらゆる分野で活躍させれば、20世紀全体で起きたような劇的な変化が数年で起きる
SITUATIONAL AWARENESS今井さん:今のAIの開発競争は、先にゴールに到達したものが現在の人間社会に存在する知能タスク全てを機械によって実行可能になる権利を手にするのと同程度の意味を持ちます。
最先端レースをしている一部のGAFAMなどの経営陣や研究者は、もはや具体的なサービスが構想にあるというよりは、上記のような発想で勝者総取りの気分でやっている気がします。特にOpenAIとマイクロソフトはその傾向が強いです。
ひろゆきさん:AI研究のゴールが、AIによるAIの研究だとすると、確かに分かりやすいですね。そして、人間は置いてけぼりになるというターミネーターなどのSFで、ありがちな設定が現実に。。。
人間の試行錯誤を機械化して進めるのでは歯が立たないわけで、、、ノーベル賞の全ての分野がAI利用になるのは時間の問題かもしれないですね、、

AI研究者,博士(工学,東京大学)
今井翔太さん(@ImAI_Eruel)
1994年、石川県金沢市生まれ。東京大学大学院 工学系研究科 技術経営戦略学専攻 松尾研究室にてAIの研究を行い、2024年同専攻博士課程を修了し博士(工学、東京大学)を取得。人工知能分野における強化学習の研究、特にマルチエージェント強化学習の研究に従事。ChatGPT登場以降は、大規模言語モデル等の生成AIにおける強化学習の活用に興味。生成AIのベストセラー書籍『生成AIで世界はこう変わる』(SBクリエイティブ)著者。その他書籍に『深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版』(翔泳社)、『AI白書 2022』(角川アスキー総合研究所)、訳書にR.Sutton著『強化学習(第2版)』(森北出版)など

ひろゆきさん(@hirox246)
本名・西村博之。1976年生まれ。「2ちゃんねる」開設者。東京プラス株式会社代表取締役、有限会社未来検索ブラジル取締役など、多くの企業に携わり、プログラマーとしても活躍する。2005年に株式会社ニワンゴ取締役管理人に就任。06年、「ニコニコ動画」を開始。09年「2ちゃんねる」の譲渡を発表。15年に英語圏最大の匿名掲示板「4chan」の管理人に。著書に『働き方 完全無双』(大和書房)『プログラマーは世界をどう見ているのか』(SBクリエイティブ)『1%の努力』(ダイヤモンド社)など多数。ABEMAで配信中の『世界の果てに、ひろゆき置いてきた』も好評
今井翔太さん写真/桑原美樹
ひろゆきさん写真/赤松洋太
編集/玉城智子(編集部)


RELATED関連記事

「中級レベルのエンジニアなら生き残れる」生成AIの進化に負けない理系人材の能力とは?【今井翔太が回答】

縦割り排除、役職者を半分に...激動の2年で「全く違う会社に生まれ変わった」日本初のエンジニア採用の裏にあった悲願

社会で成功するゲーマーに、ひろゆきが聞く「現実世界を攻略できないゲーマーに足りないものって何すか?」

優秀なエンジニアは「コードが汚いから読めない」なんて言わない【ひろゆき×安野たかひろ】

「技術だけで、良いものは作れない」ヒットメーカー糸井重里が半世紀働いて気付いた、熱狂を生むプロダクトに不可欠なもの

元テスラのマネジャー上田北斗氏が、イーロン・マスクに学んだ「First principles thinking」とは
JOB BOARD編集部オススメ求人特集








RANKING人気記事ランキング

孫正義に未来を宣言した20代の野心。「No.1」を譲らない木口佳南を突き動かす原動力

「休める仕組み」が強い開発チームを作る。主力エンジニアの3カ月育休を支える“失敗を許容する”空気感

南場智子「ますます“速さ”が命題に」DeNA AI Day2026全文書き起こし

「未来はすでにここにある」暦本純一が最終講義で語った、これから10年の技術者の仕事

AWS認定資格12種類を一覧で解説! 難易度や費用、おすすめの学習方法も
タグ
そのほかのタグを見る



